(37)
(37)
 (0)
(0)
 收藏
收藏

“我们实验室在黄浦江畔,希望成为我国人工智能产业的源头,为产业生态提供基座和支撑。”站在西岸国际人工智能中心37层的落地窗前,上海人工智能实验室领军科学家林达华教授告诉解放日报·上观新闻记者。透过窗户,可俯瞰上海西岸的浦江美景。
近日举行的上海科技创新成果展上,上海人工智能实验室研发的“书生”通用大模型体系亮相人工智能展区。在国内外“百模大战”的背景下,这个大模型体系显得与众不同——体系内多个大模型向全社会开源,并给予企业和开发者免费商用授权;其中,“书生·浦语”是全球首个贯穿数据、训练、评测等环节的全链条大模型开源体系,不仅开源了基座模型,还开源了研发大模型的整条工具链,在“授人以鱼”的基础上“授人以渔”。
“书生”为何要走这样一条全面开源之路?
集聚青年人才和算力数据资源
对于开源,林达华很有发言权。在麻省理工学院获得博士学位后,他回到以前就读的香港中文大学,发起计算机视觉算法开源项目OpenMMLab。在他的推动下,OpenMMLab成为深度学习时代具有全球影响力的视觉智能开源平台,已开放2500多个算法模型,被140多个国家和地区的上百万开发者采用。
上海人工智能实验室成立后,林达华随汤晓鸥教授来到了这家新型研发机构。在汤晓鸥领导下,实验室以国际视野集聚了一大批优秀青年人才,开展战略性、原创性、前瞻性的科学研究和技术攻关,力求突破人工智能的重要基础理论和关键核心技术,支撑我国人工智能产业实现跨越式发展。基于这个定位,实验室注重研发开源类产品,为构建产业创新生态服务。
 林达华在2023世界人工智能大会上发布“书生·浦语”开源体系。
林达华在2023世界人工智能大会上发布“书生·浦语”开源体系。
随着ChatGPT的问世,人工智能进入了大模型时代。为发挥新型研发机构的战略价值,上海人工智能实验室集聚了大规模算力和数据资源,组建了平均年龄不到30岁的大模型研发团队。这个团队的青年人才中,有些是来自国内外知名高校的博士,有些是来自顶尖企业的工程师。团队中也有人文社会科学专家,他们参与了大模型的价值对齐工作,让“书生”生成的内容符合我国主流价值观。
 “书生·浦语”能识别出用户问题中的不安全因素,并给出正确的价值引导。
“书生·浦语”能识别出用户问题中的不安全因素,并给出正确的价值引导。
三大模型实现国内和全球首个
经过一年多奋战,“书生”通用大模型体系已开发成功并多次迭代。这个体系包含国内首个支持长语境的多语言千亿参数大模型“书生·浦语”、国内首个支持开放世界百万语义标签理解的“书生·多模态”大模型、全球首个城市级三维空间大模型“书生·天际”。
作为一个对标GPT系列的大语言模型,“书生·浦语”掌握多种语言,具备理解长输入文字、展开复杂推理、进行长时间多轮对话的能力;能通过表格和图表等方式,汇总与呈现复杂信息;具有较强的数值计算、函数运算、方程求解等数理能力。它的安全和对齐能力也很强,能可靠地遵循人类指令,在收到包含错误价值观的指令后会准确指出问题,并予以纠正。
在很多主流评测集中,“书生·浦语”表现出优越的综合性能,在35个评测集上的性能得分高于ChatGPT。
“山峰高耸入云天,云雾缭绕自成烟。忘身物外心自适,静听松涛入画眠。”这是“书生·多模态”在用户输入张大千画的《湖山清夏图》后,创作的一首七言绝句,读来颇有诗味。这个大模型包含200亿参数,支持多模态生成和跨模态交互,并支持350万语义标签的识别和理解,覆盖开放世界常见的类别和概念。
 “书生”根据张大千《湖山清夏图》创作的七言绝句
“书生”根据张大千《湖山清夏图》创作的七言绝句
“书生·天际”由上海人工智能实验室与香港中文大学、上海市测绘院联合研发,能以4K级图像精度准确呈现三维城市场景,对100平方公里范围进行实景建模,并具备高精度实时渲染以及城市级编辑、风格化转换等功能。
林达华介绍,在研发这三个大模型过程中,他们攻克了多项关键核心技术,如高质量的数据清洗、预训练算法开发、数千张GPU(图形处理器)高效并行运算。“决定大模型质量的首要因素是数据质量,所以实验室联合中央广播电视总台等十多家单位,发起成立了中国大模型语料数据联盟。”这个联盟提供的语料不仅用于训练“书生”,还通过开源开放,为学术界和产业界提供符合中文主流价值观的高质量数据。
创新策源繁荣大模型产业生态
在全面开源之路上,语料数据是一个环节,从基座模型到预训练、微调、部署、评测等各个环节,上海人工智能实验室都有开源产品发布,让企业、高校院所的研发团队和个人开发者可利用这些成果,“白手起家”打造出各种大模型产品。
为了降低“书生·浦语”的开源门槛,实验室研发团队对它进行了瘦身,开发出200亿(20B)参数“中量级”版本。“在有限的参数规模下,我们做架构设计时面临取舍——是做强模型的深度还是宽度?”林达华说,“通过很多对照实验,我们发现更深的模型有利于培养复杂推理能力,所以把模型层数设定为60层,超过大多数‘中量级’模型层数。”后来的评测证明,这个选择是对的,“书生·浦语”20B的综合性能不仅全面领先相近量级的开源模型,而且以不足三分之一的参数量,达到了国际开源模型标杆Llama2-70B的评测成绩。
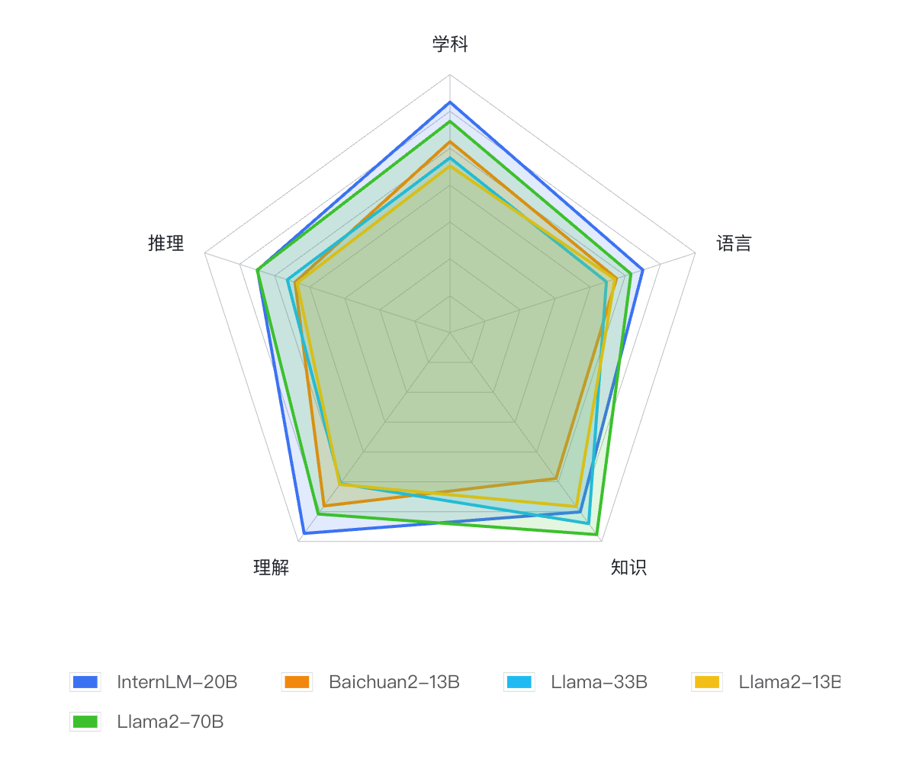 基于OpenCompass的InternLM(书生·浦语)20B及相近量级开源模型测评结果
基于OpenCompass的InternLM(书生·浦语)20B及相近量级开源模型测评结果
目前,“书生·浦语”已授权通信、金融、高端制造业等国家重点行业企业使用,如用于中国电信,上海人工智能实验室在与中国电信合作,开发更智能化的客服系统。
在传媒行业,“书生”也大有用武之地。实验室与中央广播电视总台联合发布了“央视听媒体大模型”,让一些媒体从业者有望在与大模型“聊天”中完成工作。比如输入一段视频,大模型就能创作出解说词和新闻稿,并有多种风格供选择;输入一个文本,大模型则能直接生成相关视频,其质量可达到高清视频标准(2K和24FPS),而且有故事情节和镜头连贯性。据透露,实验室正在与总台共同制作我国首部完全由AI生成的动画片。
实验室还推出了图文混合创作大模型“书生·浦语灵笔”。开源以来,在不到2个月时间里,模型代码被各国开发者下载1.7万次,在线展示体验模块试用超17万次。
“2023至2025年,是大模型技术创新和产业生态发展的关键时期。”上海人工智能实验室产业生态负责人表示,“我们实验室构建了开源技术体系,希望成为繁荣大模型产业生态的创新策源地。”
在林达华看来,国内企业要找准定位,不一定投入大量财力人力开发基座模型,而是可以利用开源的“书生”大模型体系及其工具链,以更低成本、更高效地开发各种大模型应用产品。
 我也说两句
我也说两句



































































 沪公网安备 31010602000361号
沪公网安备 31010602000361号