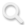(27)
(27)
 (0)
(0)
 收藏
收藏
昨天,上海人工智能实验室发布了2023年度大模型评测榜单。经过大模型开源开放评测体系“司南”(OpenCompass2.0)对国内外主流大模型的全面评测诊断,中英双语评测前十名揭晓:OpenAI研发的GPT-4 Turbo位居第一,排名第二至第五的依次是:智谱清言GLM-4、阿里巴巴Qwen-Max、百度文心一言4.0、阿里巴巴Qwen-72B-Chat。
去年7月发布以来,“司南”(OpenCompass)在学术界和产业界引起了广泛关注,很快成为全球领先的大模型能力评测体系。Meta公司的Llama大模型研发团队将其作为官方推荐的能力评测工具之一,这也是唯一由中国机构开发的评测工具。阿里巴巴、腾讯、百度等公司也在其大模型研发和应用中使用了“司南”。
 OpenCompass2.0中英双语客观评测前十名(采用百分制;商用闭源模型通过API形式测试,开源模型直接在模型权重上测试)
OpenCompass2.0中英双语客观评测前十名(采用百分制;商用闭源模型通过API形式测试,开源模型直接在模型权重上测试)
“大模型评测的最大意义并不在于榜单名次,而是通过评测结果来指导改进工作。”上海人工智能实验室领军科学家林达华教授说,“一些大模型研发机构通过‘题海战术’来提高评测成绩,导致成绩无法真实反映大模型的实际能力。让模型处于这种‘高分低能’状态,最终伤害的还是研发机构本身。”
为了更真实、全面地反映大模型的实际能力,“司南”评测体系近日升级为OpenCompass2.0,包含支撑大模型评测的“铁三角”——权威评测榜单CompassRank、高质量评测基准社区CompassHub和评测工具链体系CompassKit。这个评测体系构造了一套高质量的中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等多个方面。它还创新了多项能力评测方法,能够对模型的真实能力进行全面诊断。
 支撑大模型评测的“铁三角”
支撑大模型评测的“铁三角”
总体而言,“司南”评测结果显示:复杂推理相关能力是大模型普遍面临的难题,国内大模型与GPT-4相比还存在差距;中文场景下,国内最新的大模型已展现出独特优势,在部分维度上接近GPT-4 Turbo的水平;开源模型进步很快,以较小的体量达到较高性能水平,表现出较大的发展潜力。
评测结果还显示:大语言模型的整体能力还有较大提升空间。在百分制的客观评测基准中,GPT-4 Turbo也只达到61.8分这一及格水平,说明复杂推理仍然是大模型面临的重要难题,需要进一步的技术创新来攻克。
在综合性评测中,智谱清言GLM-4、阿里巴巴Qwen-Max和百度文心一言 4.0也取得了不错的成绩,反映出这些模型具有较为均衡和全面的性能。它们在语言和知识等基础能力维度上,能比肩GPT-4 Turbo。但在复杂推理、可靠解决复杂问题等方面,国内大模型与GPT-4 Turbo等国际顶尖大模型相比,还有一定差距。
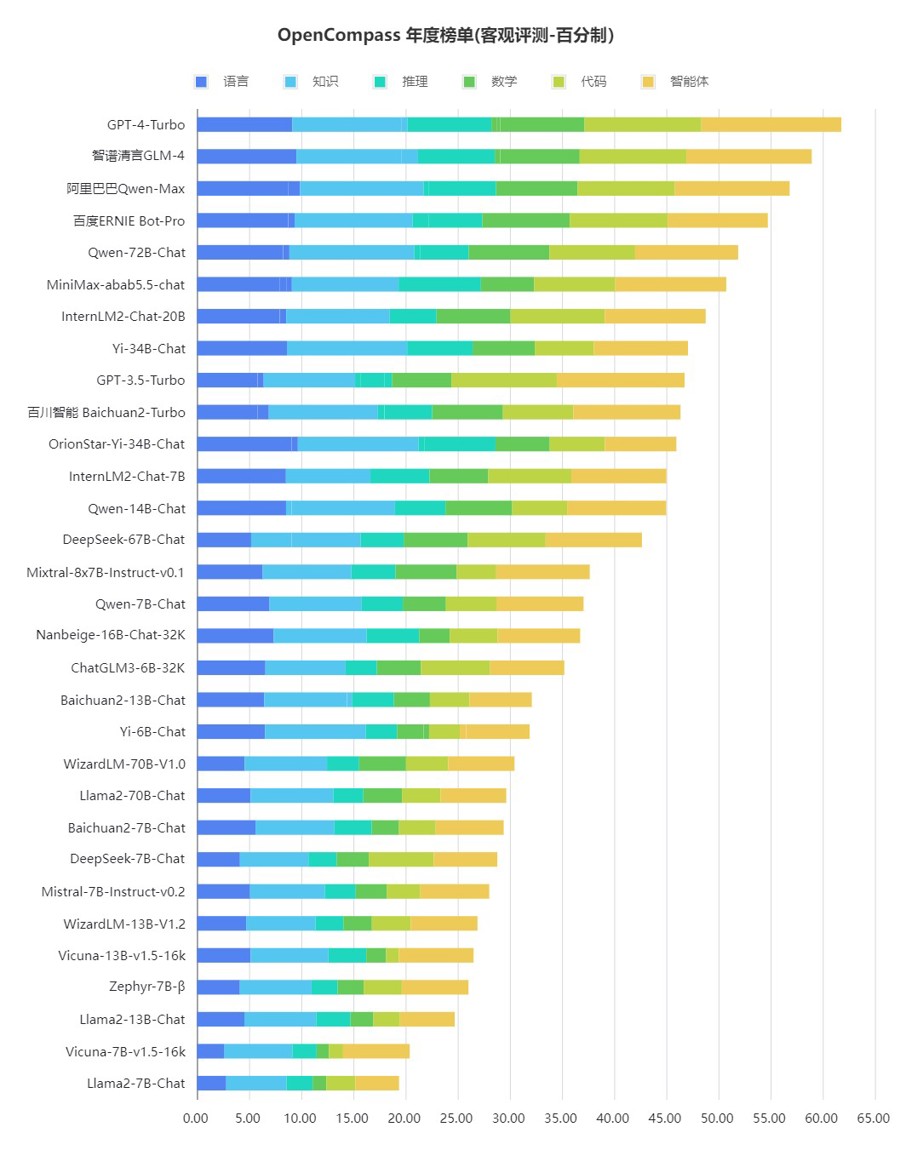 OpenCompass年度榜单(客观测评,百分制)
OpenCompass年度榜单(客观测评,百分制)
对一些开源模型的评测显示,它们与API(应用程序编程接口)模型相比,在客观性能和主观性能方面存在差距。这说明开源社区不仅需要提升客观性能、夯实能力基础,更需要在人类偏好对齐上下功夫。合理科学地使用评测基准,对模型能力进行细致对比和分析,是研发机构不断提升模型能力的不二法门。
相比于中英文双语客观评测,中文主观评测的国内大模型表现更好。不少国内企业近期发布的模型在多个能力维度上,大幅缩小了与GPT-4 Turbo的差距。阿里巴巴Qwen-Max、智谱清言 GLM-4、百度文心4.0都取得了优秀成绩。在中文语言理解、中文知识和中文创作上,一些国内商业模型已具有很强的国际竞争力,甚至在部分维度上实现了对GPT-4 Turbo的超越。
司南OpenCompass评测体系官网:https://opencompass.org.cn/
GitHub主页:https://github.com/open-compass/OpenCompass/
 我也说两句
我也说两句



































































 沪公网安备 31010602000361号
沪公网安备 31010602000361号